Machine Learning Applications In Software Engineering

Providing an overview of machine learning, this text summarizes the state-of-the-practice in this niche area, gives a classification of the existing work, and offers application guidelines.
There exists a wide spectrum of the availabilities for data and domain theories (models) in software engineering tasks. Quantitatively, some tasks may be data-rich while others data-poor; qualitatively, available data may be ranging from noisy, incomplete to accurate, adequate. On the other hand, the availability of a domain theory (a model or models, or some background knowledge) for a given SE task may vary from correct and complete, to inaccurate or incomplete, or to nonexistent.
Two paradigms exist in ML: inductive (or empirical) learning and analytical learning, and comparison of the two yields the following result in Table 29 [105].
| Inductive Learning | Analytical Learning | |
|---|---|---|
| Objective | Formulate general hypotheses that fit observed training data | Formulate general hypotheses that fit domain theory |
| Justification | Statistical inference | Deductive inference |
| Advantage | Require no prior knowledge | Learn from scarce data |
| Disadvantage | Can fail if there exist scarce data, or incorrect inductive bias | Can be misled when given incorrect or insufficient domain theory |
| Method | DT, NN, GA, ILP | AL, EBL |
Because the availability and utilization of data and domain theory play a pivotal role in these two paradigms (learning objectives, complementary merits and demerits), we can use data and domain theory as guiding factors in considering the adoption of learning methods (Figure 13).
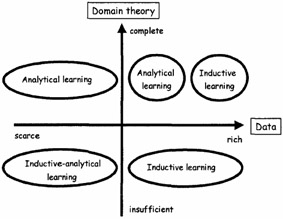
When a given task is data-rich, methods of inductive learning can be considered. If there exists a well-defined model for a...







