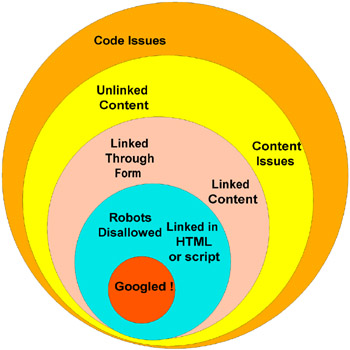
Google Hacking for Penetration Testers

Borrowing the techniques pioneered by malicious "Google hackers," this book aims to show security practitioners how to properly protect clients from this often overlooked and dangerous form of information leakage.