Database Tuning: Principles, Experiments, and Troubleshooting Techniques

Learn to improve transferable skills that will facilitate in tuning many database systems on numerous hardware and operating systems.
Nearly all the database systems sold today are relational not bad for a data model that was dismissed as totally impractical when Ted Codd first introduced it in the early 1970s (shows you how much to trust critics). The relational model offers a simple, more or less portable, expressive language (usually SQL) with a multitude of efficient implementations.
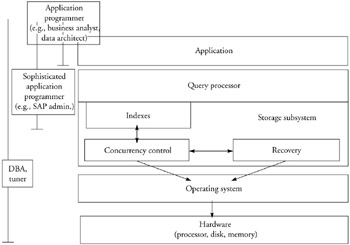
Because of the spectrum of applications that relational systems cover, making them perform well requires a careful analysis of the application at hand. Helping you do that analysis is the goal of this chapter. The analysis will have implications for lower-level facilities, such as indexes and concurrency control. This chapter, however, discusses higher-level facilities (Figure 4.1). The discussion will concentrate on four topics.
Table (relation) design trade-offs among normalization, denormalization, clustering, aggregate materialization, and vertical partitioning. Trade-offs among different data types for record design.
Query rewriting using indexes appropriately, avoiding DISTINCTs and ORDER BYs, the appropriate use of temporary tables, and so on.
Procedural extensions to relational algebra embedded programming languages, stored procedures, and triggers.
Connections to conventional programming languages.
One of the first steps in designing an application is to design the tables (or relations) where the data will be stored. Once your application is running, changing the table design may require that you change many of your application programs (views don't work for most updates). So, it is important to get the design right...