7.2.1.1 Instruction Counting When it is too early for the logic analyzer,
or if one is not available, instruction counting is the best method of determining
CPU utilization due to code execution time. This technique requires that the code
already be written, that an approximation of the final code exist, or that similar
systems be available for inspection. The approach simply involves tracing the
longest path through the code, counting the instruction types along the way, and
adding their execution times.
Of course, the actual instruction times are required beforehand. They then can
be obtained from the manufacturer’s data sheets, by timing the instructions using
a logic analyzer or simulators, or by educated guessing. If the manufacturer’s
data sheets are used, memory access times and the number of wait states for each
instruction are needed as well. For example, consider, in the inertial measurement
system. This module converts raw pulses into the actual accelerations that are
later compensated for temperature and other effects. The module is to decide if the
aircraft is still on the ground, in which case only a small acceleration reading by
the accelerometer is allowed (represented by the symbolic constant PRE_TAKE).
Consider a time-loading analysis for the corresponding C code.
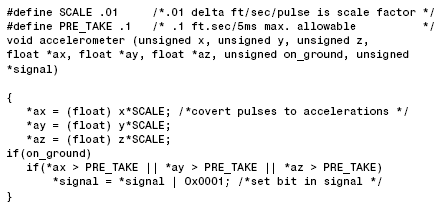
A mixed listing combines the high-order language instruction with the equivalent
assembly language instructions below it for easy tracing. A mixed listing
for this code in a generic assembly language for a 2-address machine soon
follows. The assembler and compiler directives have been omitted (along with
some data-allocation pseudo-ops) for clarity and because they do not impact the
time loading.
The instructions beginning in “F” are floating-point instructions that require
50 microseconds. The FLOAT instruction converts an integer to floating-point
format. Assume all other instructions are integer and require 6 microseconds:

Tracing the worst path and counting the instructions shows that there are 12 integer
and 15 floating-point instructions for a total execution time of 0.822 millisecond.
Since this program runs in a 5-millisecond cycle, the time-loading is 0.822/5 = 16.5%.
If the other cycles were analyzed to have a utilization as follows – 1-second
cycle 1%, 10-millisecond cycle 30%, and 40-millisecond cycle 13% – then the
overall time-loading for this foreground/background system would be 60.5%.Could
the execution time be reduced for this module? It can, and these techniques will be
discussed shortly.
In this example, the comparison could have been made in fixed point to
save time. This, however, restricts the range of the variable PRE_TAKE, that
is, PRE_TAKE could only be integer multiples of SCALE. If this were acceptable,
then this module need only check for the pretakeoff condition and read the direct
memory access (DMA) values into the variables ax, ay, and az. The compensation
routines would perform all calculations in fixed point and would convert
the results to floating point at the last possible moment.
As another instruction-counting example, consider the following 2-address
assembly language code:

Calculate the following:
- The best- and worst-case execution times.
- The best- and worst-case execution times. Assume a three-stage instruction
pipeline is used.
First, construct a branching tree enumerating all of the possible execution paths:
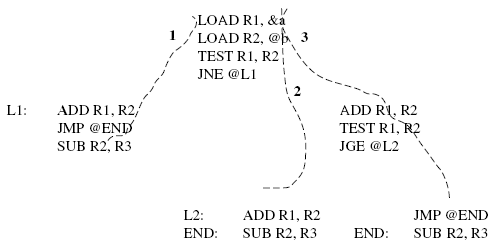
Path 1 includes 7 instructions@ 6 microseconds each = 42 microseconds. Path 2
and 3 include 9 instructions @ 6 microseconds each = 54 microsends. These are
the best- and worst-case execution times.
For the second part, assume that a three-stage pipeline consisting of fetch, decode,
and execute stages is implemented and that each stage takes 2 microseconds. For
each of the three execution paths, it is necessary to simulate the contents of the
pipeline, flushing the pipeline when required. To do this, number the instructions
for ease of reference:

If “Fn,” “Dn,” and “En” indicate fetch, decode, and execution for instruction n,
respectively, then for path 1, the pipeline execution trace looks like:
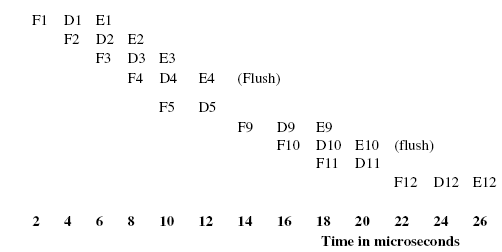
This yields a total execution time of 26 microseconds.
For path 2, the pipeline execution trace looks like:
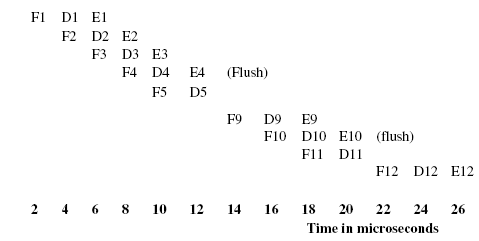
This represents a total execution time of 26 microseconds.
For path 3, the pipeline execution trace looks like
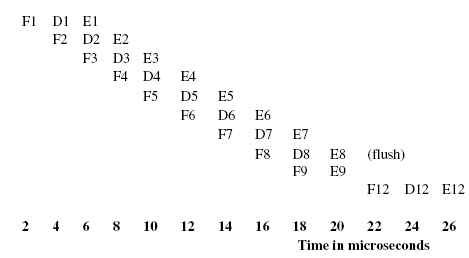
This yields a total execution time of 26 microseconds. It is just a coincidence
in this case that all three paths have the same execution time. Normally, there
would be different execution times.
As a final note, the process of instruction counting can be automated if a parser
is written for the target assembly language that can resolve branching.
© 2004
 This book is an introduction to real-time systems. It is intended not as a cookbook,
This book is an introduction to real-time systems. It is intended not as a cookbook,






