Introduction to Genetic Algorithms

Including numerous hands-on problems and solutions, this comprehensive book is a helpful guide and a valuable source of information about Genetic Algorithm concepts for their several practical applications.
In the previous chapter we have dealt with simple genetic operators: reproduction, cross over and mutation. In this chapter we consider natural operators and phenomena to improve the robustness of simple genetic algorithms. The low-level operators like dominance, inversion, recording, deletion, segregation and diploidy are discussed here. Also, the higher-level operators like niche and speciation are induced. Multi-objective optimization and knowledge-based techniques are also considered for discussion in this chapter.
Till now, we have considered only the simplest genotype existing in the nature, the haploid or single chromosome. A haploid chromosome contains only one set of genes i.e., one allele to occupy each locus. Nature consists of many haploid organisms, but most of them tend to uncomplicated life form. When nature wants to construct a more complex or animal life to rely upon, a more complex underlying chromosome structure is needed and this is achieved by the diploid or double-stranded chromosomes. In the diploid form, a genotype carries one or more pairs of chromosomes, each containing information for the same function. Consider a diploid chromosome structure where different letters represent different alleles (different gene function values):
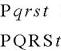
Allele represents the property of a particular gene. Each locus of a letter represents one allele. The uppercase and the lowercase letters mentioned above represent the alternative alleles at that position. Originally, in nature each allele may represent different phenotypic properties. For example Q may represent gray haired gene and q may be black haired...







