Neural Networks for RF and Microwave Design

An electrical engineering textbook on practical applications of artificial intelligence technology methods to solving complex radio-frequency and microwave design problems.
The BP algorithm based upon the steepest descent principle is relatively easy to implement. The error surface of the training objective function, however, contains planes with gentle slopes, as a result of commonly used logistic activation functions. The values of the error gradient are too small for the weights to move rapidly on these planes, and thus the rate of convergence is slowed down. The rate of convergence also gets slow when the steepest descent method encounters a "narrow valley" in the error surface, in which the direction of gradient moves close to the perpendicular direction of the valley.
Because supervised learning of neural networks can be viewed as a function optimization problem, higher-order optimization methods using gradient information can be used for neural network training in order to improve the rate of convergence. Compared to the heuristic BP algorithm, these methods have a sound theoretical basis and guaranteed convergence. Early work in this area was demonstrated in [28] and [29], with the development of second-order training algorithms for neural networks.
The conjugate gradient methods originally derived from quadratic minimization, in which the minimum of the objective function E T, can be efficiently found within N w iterations. With initial gradient 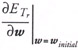 , and direction vector h initial = - g initial, the conjugate gradient method recursively constructs two vector sequences [30]
, and direction vector h initial = - g initial, the conjugate gradient method recursively constructs two vector sequences [30]
| (4.43) | |
| (4.44) | |
| (4.45) | 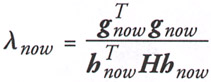 |
| (4.46) | 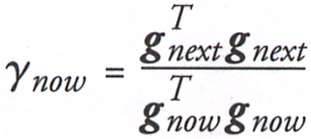 |
| (4.47) | 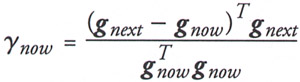 |







